For years I’ve been getting an email from LinkedIn that looks like this:
Curiously, this is the only skill assessment I’ve been invited to take since my title changed to data scientist in 2016. If the reason they’re recommending it is factual (i.e., it will help me “stand out to recruiters”), this can be seen as a sign that many organizations are pushing for “Agile adoption” in data science.
And the reality is that this call for action always has the opposite effect on me: it makes me want to avoid any association between my profile and “Agile Methodologies.” Let me explain why.
Does it make sense to merge Agile philosophies with data science?
The short answer is yes, as long as the organization recognizes and accommodates the ambiguous, non-linear nature of the data science process rather than expecting data scientists to fit into the same mold they’ve adopted for “Agile software development”.
The problem, in my experience, is that this rarely happens. Probably because the data science field is still new, many organizations are still trying to shoehorn data science into Agile software engineering practices that compromise the natural data science lifecycle.
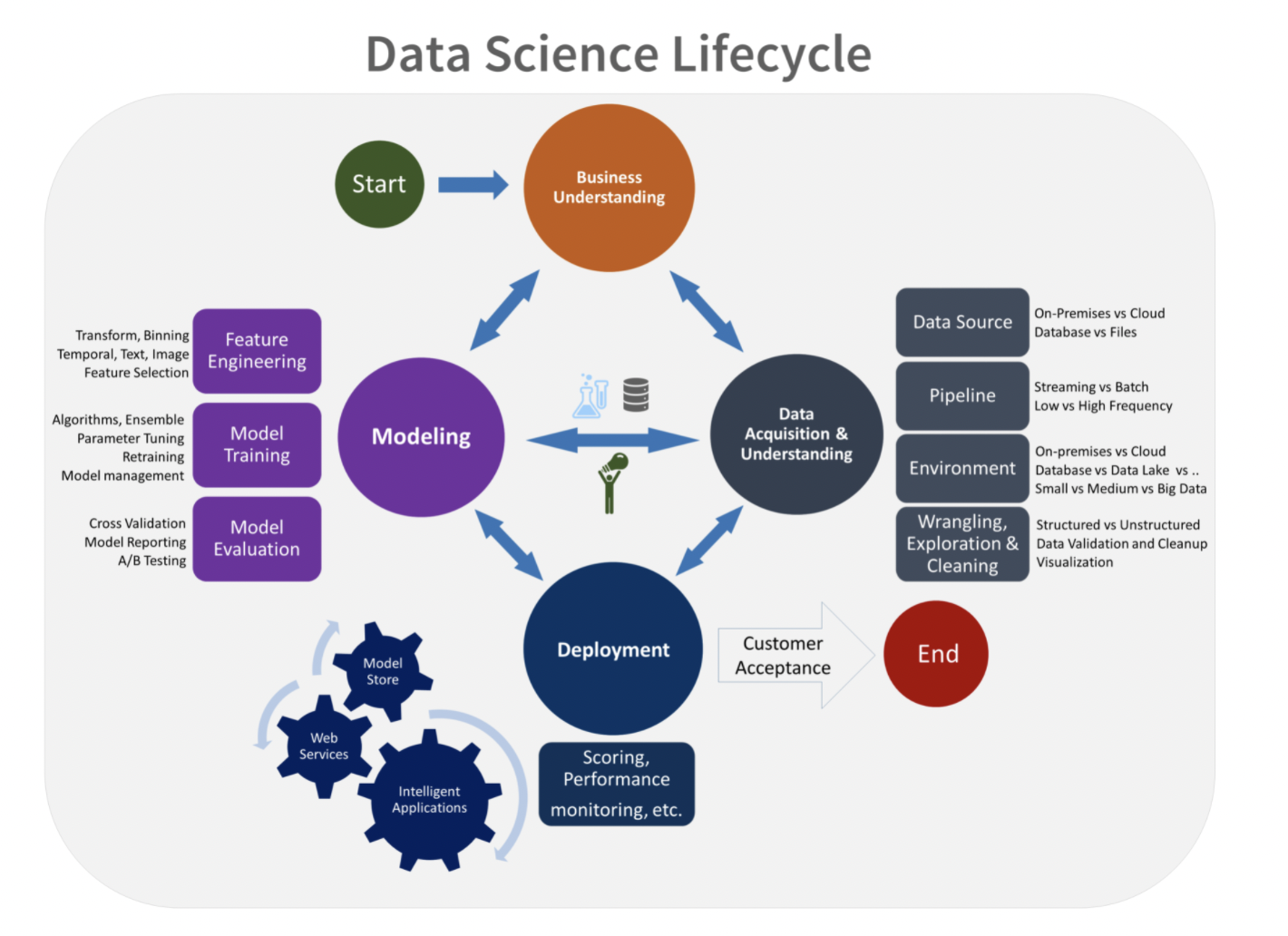
Microsoft’s Team Data Science Process (TDSP) - source
As illustrated in the diagram above, successful data science projects require a highly exploratory and iterative process that is vastly different from what works in software engineering.
On surface the two types of projects are very similar: both have a foundation on data, math, and code. They also share the need to start from a good understanding of the business problem to increase the likelihood of success. And it’s true that the work products of data science and software engineering are blending together more and more as organizations increase the deployment of data science models into overarching software systems.
Still, in many of my data science projects, before we could even start thinking about model deployment, there could be months performing data acquisition and cleaning, exploratory data analysis, feature engineering, model training, and model evaluation. Moreover, midway throughout my investigation, it often became clear we needed to shift gears:
- After finding out that measures of student performance were constantly changing, I had to modify our approach to predict academic success from supervised machine learning (which required reliable historical data) to an heuristics model that didn’t rely on past data to make accurate predictions.
- After an investigation to understand the root cause of anomalous readings of latitude and longitude generated by cheap GPS sensors failed, we shifted to researching a variety of post-processing techniques to improve the accuracy of the anomalous estimates.
Clearly, that’s very different from the typical Agile software development model in which a team is expected to deliver high-quality software at the end of each sprint.
But that doesn’t mean Agile philosophies aren’t helpful in data science projects. Agile practices can improve productivity and collaboration in data science teams and between data scientists and software developers. It can also help organizations think in terms of a “minimum viable product” to accelerate time-to-value of machine learning projects.
How Agile data science can help accelerate business results in data science projects
When done right, Agile data science can help improve the productivity of data science teams.
More than once in my career, I was hired to replace a data scientist who wasn’t making enough progress toward a business goal involving machine learning. Whether in an internal project (e.g., build a reliable model to predict customer churn) or external application (e.g., develop a risk scoring system to help nonprofits identify students in need of additional support to ensure they’d graduate from high school), the organization simply had lost trust in my predecessor’s ability to deliver results.
Agile data science can help prevent this issue. Building predictive models with real-life data takes time–potentially many months. But that doesn’t mean going away for months and coming back with a final model that may or may not suit the business needs.
A much better approach is to use Agile principles to follow the critical path to a valuable analytics product.
To illustrate how to apply Agile to data science, let’s look at an example from my own experience.
In a past job, I was hired to replace a data scientist who had spent nearly a year analyzing data without producing a single usable model. Obviously, by the time I joined the team, the business was impatient for results, having waited so long already.
I knew that achieving the desired future state of a highly accurate predictive model that improved business decision-making would take months. Thankfully, at that job I didn’t have to deal with a Scrum master trying to shoehorn my work into their regular software development agile process. I was allowed to design my own Agile data science process.
In my self-designed process, there were no user stories. I'd add tasks to a backlog and then prioritize them based on their importance to our critical path. Each task would be associated with a work product, so the progress achieved was clear to everyone.
For example, in a project to investigate the feasibility of using machine learning to predict patient outcomes based on diagnosis and treatment data, my task list might include the following:
Goal: Reduce the number of patient diagnostic codes so that instead of 5,000 values, many of which indistinguishable from each other for our purposes, our model can be fed with a smaller number of diagnosis levels and learn relevant patterns from them.
|_ Task 1: Interview one or more specialists in medical data to understand the most meaningful ways to aggregate different diagnostic codes into an “umbrella” code.
Output: A document describing the approach to be taken to aggregate diagnosis codes into a smaller number of diagnosis levels.
|_ Task 2: Develop the code to transform the raw data containing high-granularity diagnosis codes into the final diagnosis attribute ready to be fed into the model.
Output: A notebook with Python code that uses as input the high-granularity diagnosis codes and outputs a smaller number of diagnosis levels.
I didn’t bother to size my tasks or have an “active sprint” during which I’d move tickets through various stages from “in development” to “done”. But I did have a list of prioritized in-progress activities that would go to the “done" state as I finished them.
This approach prevented any misalignment between my work and the work of other parts of the organization. Data engineering gained visibility sooner into input data I’d need them to add to a data pipeline. Business stakeholders always knew how close I was to answering the business question. No one had to wonder what the data scientist on the team was doing as I performed exploratory data analysis and applied research to move us closer to the end goal.
As usual, the devil is in the details
As with any other organizational effort, data science projects can benefit from Agile approaches that quickly adapt to and even anticipate and lead change. We shouldn’t forget that the ideas behind Agile methodologies started outside software engineering, in lean manufacturing and organizational learning. And that valuable Agile practices like stand-up meetings and prioritization also existed long before the Agile Manifesto.
Still, especially in organizations that heavily rely on Agile software development, the first step toward establishing a successful Agile data science process is recognizing and accepting the differences between the two fields.
As a data scientist, I welcome Agile approaches as long as the organization understands how working software should not be the primary measure of progress in my data science projects.
As I wrote in a post on the absurdity of employee tracking software,
The most progress I make as a data scientist tends to happen when I'm talking to subject matter experts or taking a walk to clear my mind--not when I'm sitting in front of the computer typing away or showing as "active" in Slack or Teams.
Sadly, many organizations insist on replicating their software development Agile process in their data science projects. I’ve worked for several organizations that excelled in Agile software development and then experienced significant failure when trying to replicate the same successes in their data science projects.
For example, while working as a data scientist on an asset tracking project, I envied software engineers who’d be working on user stories like this: “As a construction site manager, I can see, on the screen where the estimated location of a piece of equipment is displayed, a confidence interval (e.g., +/- 5 meters) so that I know how accurate the reported position estimate is.”
Of course the engineer in charge of that story could very confidently estimate how long it would take to implement it (half a day, three days, five days). During story grooming, a business analyst had already identified from which database table and column to retrieve the value to be displayed, and a UX designer had created a mock-up showing where and how to display the confidence interval next to the location estimate of each asset.
My job, on the other hand, was on the R&D side, trying to answer questions like, “How might we reduce the error on estimated asset locations?” The time required to get to a suitable answer might vary from days to several months, with no guarantee that I’d reach a viable solution by the end of a sprint.
In data science projects the solution space tends to be much larger, with many things to try, from supervised and unsupervised learning to similarity-based recommendation systems and reinforcement learning. That leads to difficulty in estimating the number of experiments needed and the effort of each experiment.
The sooner organizations get used to those differences and focus on agility rather than fixating on Agile ceremonies, the sooner they’ll start reaping the benefits of Agile data science.
In the words of professor Michael A. Cusumano of MIT Sloan School of Management:
“[Agility] comes in different forms, but basically it’s the ability to quickly adapt to or even anticipate and lead change.
Author: Adriana Beal, Data Scientist
Adriana Beal has been working as a data scientist since 2016. Her educational background includes graduate degrees in Electrical Engineering and Strategic Management of Information obtained from top schools in her native country, Brazil and a certificate in Big Data and Data Analytics from the University of Texas. Over the past five years, she has developed predictive models to improve outcomes in healthcare, mobility, IoT, customer science, human services, and agriculture. Prior to that she worked for more than a decade in business analysis and product management helping U.S. Fortune 500 companies and high tech startups make better software decisions. Adriana has two IT strategy books published in Brazil and work internationally published by IEEE and IGI Global. You can find more of her useful advice for business analysts at bealprojects.com.