Introduction
Strategists, architects, process experts, software developers, data managers and other professionals involved in changing the enterprise often put substantial effort in creating all kinds of useful models of their designs. In many cases, such business models, enterprise architecture models, business process models, software models, or data models are only used to specify some design, i.e. to describe what should be built.
But there is much more value to be had from these models, by using powerful analysis techniques to elicit new insights. In the following pages I will cover 7 of these analyses, discussing the business outcomes you can achieve with their help. These are:
- Impact analysis
- Dependency analysis
- Process analysis
- Lifecycle analysis
- Business and technical value analysis
- Financial analysis
- Risk, security, and compliance analyses
So, without further ado, let’s get started with the first type of analysis.
Impact Analysis
Running an impact analysis is a great way to provide business-focused information on the health of your IT landscape. As such, being able to traverse the relationships within your models in a straightforward fashion is key. In my day-to-day experience, I’m used to jumping from one element to another – possibly across multiple relationships or even different types of interconnected models – with the help of a simple and effective model navigator. Then, once I arrive at the element I’m looking for, I use the context menu to select, for example, a Color or Label view, as shown in Figure 1.
In this example, we navigated from a capability to the underlying applications via the business processes and functions in between. The resulting color view shows how the capabilities of the enterprise depend on support by these applications. This can be used to clarify which capabilities rely on which applications in order to identify where the impact of replacing an application may be.
Of course, in creating these types of analysis you pay close attention to the different types of relationships that you traverse. This is where the power of ArchiMate and other modeling languages comes to the fore. Because of the specific meaning of the different relationship types, you can perform these analyses at a level that would be completely impossible when you create pictures with simple boxes and lines, e.g. in PowerPoint.

Figure 1: Using the context menu to perform a Color View
With the right kind of tool support, this kind of analysis can easily be extended to address more advanced questions. For instance, having a scripting language with which to exploit the semantics of the different modeling languages you’re using will go a long way towards helping you uncover hidden value from you models.
Several of these and other analyses can be combined in multi-level metrics that provide business-focused information on the make-up and health of your IT landscape. This is useful input for application and project portfolio management, and for prioritizing and planning the requisite changes. Hopefully this has given you a good insight into how color views and heat maps can be used to depict the impact of change within your landscape.
Dependency Analysis
A related and very popular analysis technique is dependency analysis. This is typically used to analyze how different architecture elements rely on each other in the operation of the enterprise. Next to simply traversing the relationships in your models, you can also use this structure to compute aggregate properties of your architecture or processes.
This is quite useful for defining business-oriented KPIs based on various attributes of your IT landscape. For example, it can help calculate the availability of your business capabilities based on the reliability of the underlying applications, which in turn depends on that of the underlying infrastructure.
This is often an eyeopener for IT managers who think they are doing well. If a single application has a 99% availability but your business capability needs 30 of those to work in concert, your aggregate availability is less than 75% (0.9930 ≈ 0.739). A presentation by United Airlines at the Business Architecture Innovation Summit in Brussels in June 2017 addressed exactly this topic: using capabilities to define business-driven IT metrics.
For instance, consider the heat map in Figure 2 showing the availability of part of the back-office applications in a hypothetical organization. Most are green(ish), which in this color coding implies an availability greater than 98%, so not much to worry about, right?

Figure 2: Heat map showing availability of back-office applications
Now look at the partial capability map in Figure 3, which is from the same model and uses the same color coding, but shows the total availability of each capability based on all its supporting IT. That looks a lot less rosy, doesn’t it?
Using heat maps of your business capabilities like the one above immediately highlights where management needs to focus its attention, and the structure of your models allows them to drill down into the underlying issues. In the example, it might make sense to start with capabilities such as ‘Customer order management’ and their supporting IT.
Such KPIs are not just relevant for your IT service management, but can also provide strategically important inputs for business continuity and IT risk management. A related example is identifying which capabilities are at risk from underlying technology that will soon go (or already is) out of vendor support.
You can add information on the technology lifecycle from sources such as Technopedia and propagate that through your model, similar to the previous examples. This helps you prioritize areas where you need to upgrade your IT first, based on the business-critical capabilities it supports.
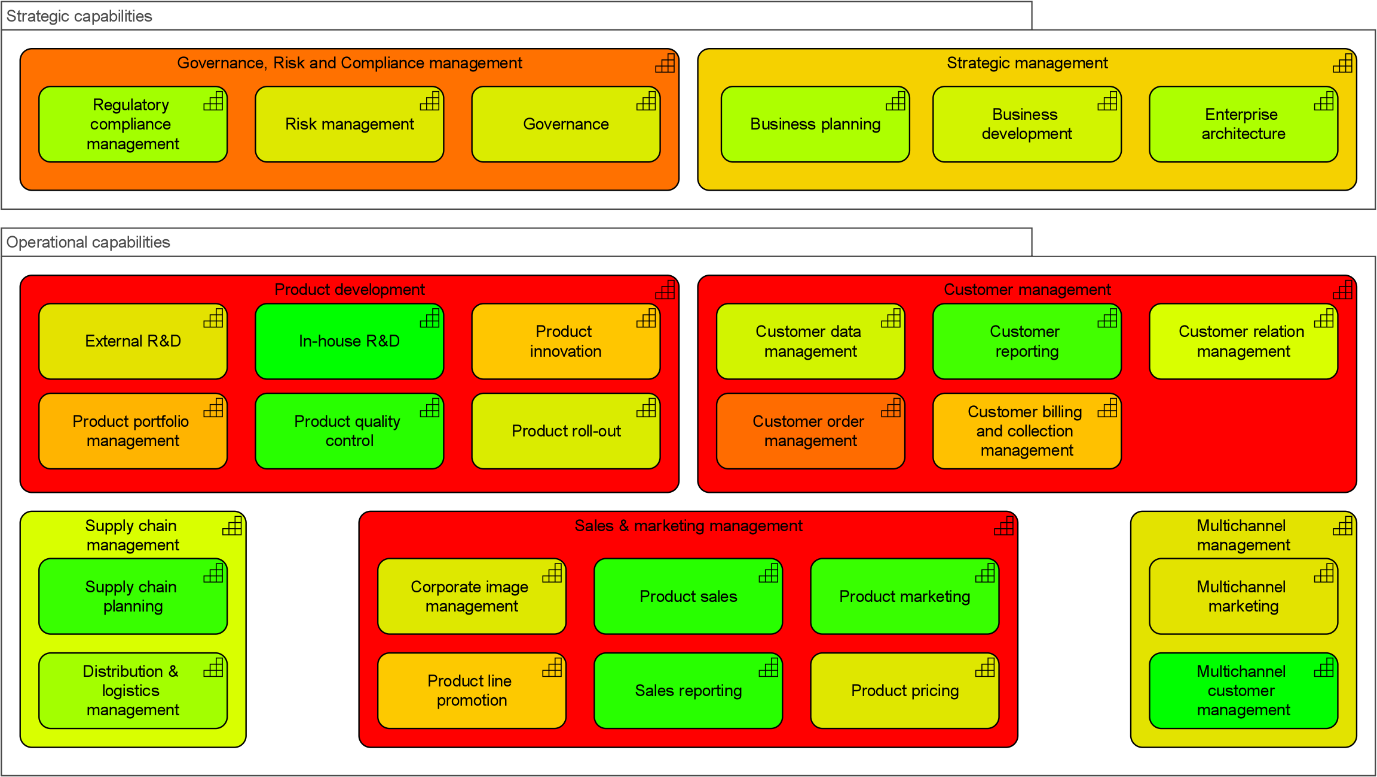
Figure 3: Partial capability map
To create these types of analysis, we use the semantics of ArchiMate’s relationships such as Serving, Realization and Flow. Having easy access to support for creating various kinds of views, analyses and dashboards, as well as some examples to build upon will of course make things significantly easier for practitioners. Hopefully these give you an indication of the many ways in which you can extract more value from your models and create business-focused KPIs and views using our platform.
Process Analysis
So far, we’ve dealt with the ‘static’ enterprise. Now we turn our attention towards the enterprise ‘in motion’ (its behavior, as it were), particularly its business processes. There are several kinds of time-based process analysis. First of all, in BPMN process diagrams users can check the syntactic consistency of your processes. Here are some simple examples out of several dozen checks:
- There must be at least one start and one end event.
- An intermediate event must have an incoming and an outgoing sequence flow.
- A gateway must have multiple incoming or multiple outgoing flows.
- Targets of an event-based gateway must not have additional incoming sequence flows.
- An end event should have a preceding condition.
Second, you can analyze various properties regarding the efficient operation of your processes, for instance in the context of Lean process management. Examples include the transfer of work between roles within a process (which you typically want to minimize to avoid time-consuming and error-prone hand-overs), or the amount of rework, i.e. loops in your process.
Third, for compliance and risk management purposes, you can cross-reference tasks and roles, or controls and risks, in order to assess whether, for instance, you have implemented separation of duties correctly, or taken the right mitigating measures against operational risks.
Finally, the most advanced types of analysis assess the behavior of processes over time. What’s key here is the ability to add information to your BPMN processes on the completion time, such as the delay, probability distribution and mean processing time. When you do that for all tasks in a business process model, you can analyze the critical path of your process and calculate how long it will take on average and what the maximum time will be.
Figure 4 illustrates this, with the labels of the tasks depicting their average processing time while in the lower left-hand corner you can see the outcome of a critical path calculation. This kind of analysis helps you find bottlenecks and unnecessary delays, and so is very useful in optimizing your business processes. Similar analyses can be made to calculate, e.g. the average cost associated with executing a process, which helps you optimize it further.
Naturally, this kind of analysis requires accurate input data, but this can be a sensitive matter, for obvious reasons. For (semi-)automated tasks, timing data can often be acquired from the IT system used. For example, in call centers, extensive statistics are kept in order to optimize processes. But for many other types of work, this information is not readily available, and people often feel threatened if you want to measure this. Given the potential misuse of this type of data, they cannot be blamed for being wary.
Moreover, they may change their behavior when you measure it, so the data will not be correct anyway. To avoid this, it has to be clear that the outcomes of such an analysis will also be used to their benefit, e.g. to reduce their work load and not just to ‘optimize’ the head count. This is an important aspect of any analysis that involves people.

Figure 4: Process showcasing time labels on tasks and the outcome of a critical path calculation
Lifecycle Analysis
You can give anything in your architecture model a lifecycle. The specific stages in those lifecycles can be defined depending on the types of objects you model. For instance, the predefined lifecycle for application components comprises the following stages:
- Definition
- Development
- Testing
- Deployment
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
- Operation
- Maintenance
- Retirement
|
In Figure 5, we show the lifecycles of some interdependent application components. In the underlying ArchiMate model, the operational stage of the Crystal Ball application depends on the Ramadera application being in operation as well, since in the architecture, Ramadera serves Crystal Ball. Similarly, Backbase CXP depends on Crystal Ball. However, Ramadera is going into maintenance and retirement before Crystal Ball, and Crystal Ball before Backbase CXP.
In this situation, analyzing the lifecycles will uncover the fact that there is a conflict between them. This is shown with red bars below the lifecycles. What’s more, hovering over this bar shows the name of the conflicting application with a tooltip.

Figure 5: Conflicting lifecycles
This works not only for elements of the same type (such as applications in this case). You can also relate different lifecycles, e.g. that an application can only go live after the project developing it has is completed and the necessary PaaS service to support it has been contracted.
Note that this is much more powerful than your regular Gantt charts for project planning. The underlying architecture model contains information on dependencies between the elements of your architecture that cannot be captured in a project planning tool. These dependencies are specific to both the types of relationships and the lifecycle stages you have, making full use of the meaning of these concepts in the ArchiMate modeling language.
For instance, if one application has a Serving relationship with another (as is the case in Figure 5), this implies a dependency between their operational stages, but not between, say, their development stages. These time-based dependencies and lifecycle stages can be further fine-tuned to make full use of any analytical capabilities that you might have at your disposal.
These types of analysis are very valuable in planning and optimizing operations and changes in your enterprise, but they don’t tell you much about the importance of these changes. For that, you need to read on ahead!
Business and Technical Value Analysis
So, how do you decide what to do with, for example, your application landscape? How do you find out which applications need to be improved, re-platformed, functionally upgraded, or phased out? The common approach for this is application portfolio management, but that doesn’t make the object of our present discussion. Here, I want to focus on the analytics behind charts such as the one in Figure 6.

Figure 6: TIME analysis
It features the typical business value and technical value axes, with the bubble size and color denoting cost and risk, respectively. This type of chart is often used in deciding on the future of applications, and in Figure 6 we see four options: Invest (red), Tolerate (blue), Migrate (yellow), and Eliminate (green). This is rather coarse-grained, so you might want to use a more detailed set of options, but in this instance I want to focus on how you calculate these values for business value, technical value and risk.
Of course, there are many factors that you may want to consider in determining the fate of your applications, so the example above is just that – an example – but it does provide good insight since it is based on an actual customer situation. As you will see below, several of the metrics we use to assess business value, technical value and risk are calculated from the structure of your architecture. This really shows the power of using models as a basis for your analyses, something you would never be able to do using simple spreadsheet calculations.
1. Business value
Let’s start with business value. In Figure 7 we see how the business value metric is constructed as a weighted average of several sub-metrics:
Strategic importance, determined by calculating an application’s contribution to business outcomes via the business processes it supports, the capabilities it enables, and the business goals these satisfy. This can be done in various ways, from high-level assessments that only determine whether an application has any influence on an outcome, to fine-grained calculations with weighted priorities on goals and strength attributes on relationships.
Importance for users is itself a weighted average of the number if effective users (those who use an application for their daily work) and the potential users (those that can use it but don’t need it, who get a much lower weight of course). Both these numbers are imported from an external source (in this case an ITSM application). The result is normalized into a [0,10] range.
Business criticality, determined by counting and normalizing the number of business-critical processes supported by that application, where process criticality itself is another metric applied to the business processes in the architecture. This metric is calculated with a script, traversing the model structure to find all the processes directly or indirectly supported by an application and taking the maximum of their criticality metric.
Importance for other applications, also a scripted metric, based on the number of outgoing relationships (the ArchiMate Triggering, Flow and Serving relationships, plus write access to data read by other applications).
The regulatory compliance level of an application, determined by counting the number of known violations of applicable regulations, normalized to a [0,10] scale. This metric requires a manual assessment by compliance officers.
The SLA compliance level of the application is the percentage of time that it is within expected performance limits, e.g. 99.9%. Like the number of users, this is based on information from an ITSM suite. This provides a percentage value that is normalized into a [0, 10] range as well.
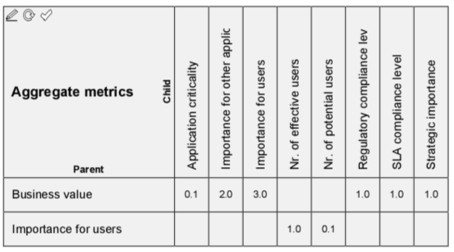
Figure 7: Business value sub-metrics
2. Technical value
The technical value of applications is determined in similar ways. The most important aspect of technical value is the technical quality of an application. This is determined by the various ‘-ilities’ known from standards such as the ISO/IEC 25010 standard for software quality. Some of these will be based on operational measurements of the application landscape. For example, the stability of an application can be based on the number and severity of incidents, while its maintainability can be measured based on the relative effort per change.
Other technical value metrics are based on the structure of the architecture and can be calculated using scripts. The (external) complexity of an application, for instance, can be determined by the number of incoming and outgoing relationships (fan-in and fan-out) of the applications. Still, other metrics require an expert opinion, such as the architectural fit of an application, the maturity of the technology used, or the quality of the documentation. Data quality is another important metric, which also requires external assessment. Metrics such as usability may be evaluated via a user survey.
Automated analysis of software code quality is normally performed by specialists. What we would be interested in this situation is the ability to easily import the outputs of such an analysis in order to power our application portfolio and lifecycle management as well. Again, different platforms will give you different capabilities and features so be sure you enquire while in the procurement process.
3. Technology risk
Another highly relevant metric for assessing applications is their technology risk, depicted with the color of the bubbles above. This aggregates a number of risk types, such as:
- End-of-support risk: Risk of an application or technology element going out of support with the vendor. The shorter the remaining lifetime, the higher this risk. This kind of data is typically provided by external sources such as Technopedia.
- Skill risk: The future availability of personnel with the requisite technical knowledge and skills to maintain an application.
- Dependency risk: The worst-case value of the end-of-support risk over all the technology on which an application depends. If an application itself is still supported by its vendor, but requires, say, Windows XP to run on, that constitutes a dependency risk.
Next to these metrics, in deciding on an application’s lifecycle you typically also use attributes like size (shown with the size of the bubbles in Figure 7), age and cost. This last one – cost – makes the subject of our next type of analysis.
Financial Analysis
Let’s focus on financial analysis, and in particular on cost models. Of course, we do not advocate to replace your regular financial calculations and metrics. Even if that were technically feasible, your financial department would never relinquish control of this, and rightly so. But what we can do, is ensure that you have an accurate overview of IT cost and the effects of changes on that.
For example, if you want to consolidate your application landscape, what are the cost drivers for these applications? What would be the best order in which to phase out or replace applications, and how will the overall IT cost develop? The structure of your architecture helps you get a clear insight into this, as I will show below. Another typical business question is how to distribute IT cost across different business units. Architecture models help you here as well.
Using ArchiMate models for IT cost calculation
To calculate the total cost of ownership of an application (or of your entire IT landscape), you would typically consider cost factors such as:
- Software cost
- Infrastructure cost
- Support cost
- Service provider cost
These metrics can be assigned to applicable elements in your architecture. For instance, software cost would be associated with application components and system software elements. Hardware costs would be related to devices and networks. Data center costs would be assigned to facilities. Support costs to the actors and processes in your IT organization. Service provider costs to (external) business, application or technology services.
But next to assessing these basic metrics, you can do more with your architecture models. If you know the relationships between, say, the applications and their supporting infrastructure, you can distribute the infrastructure costs across these applications. In its simplest form, that would be an even distribution, e.g. if five applications use the same server, each gets 20% of that server’s cost assigned.
If you know more about the actual usage, you can put that as an attribute on the relationship with the applications and do a more fine-grained calculation. The same holds for the various other costs involved, e.g. for maintenance and support or for the use of external services. Adding this all up provides you with an accurate picture of your application TCO.
Figure 8 gives you an impression of how this works. We look at the capacity needed and based on that we assign the relative cost contribution to the application.

Figure 8: ArchiMate model showing relationship between applications and infrastructure
If you do this for the basic elements in your application landscape, you can of course aggregate the cost at higher levels as well by simply adding up the cost of the components that make up larger applications, application groups/domains etc.
Combining these cost numbers with the lifecycle analysis I discussed previously provides you with an even more powerful instrument. You can follow the evolution of IT cost over time and compare alternative future scenarios, for example different ways to reduce your application landscape as in the example above, and thus maximize potential cost savings.
Of course, models like the one above is probably not something you would show to the financial professionals or executives in your organization. Rather, you would create management dashboards with charts that depict the data in a more familiar form. There, you can also cross-reference this data with other information, e.g. combining application cost with business and technical value, size, age, complexity and risk.
Figure 9 shows part of an application portfolio dashboard that combines several such metrics. As an aside, you could even do this type of calculation for the cost of the IT organization, computing for example the cost of incident management per incident (based on the cost of personnel, their office space, the tools they use etc.). However, most organizations will already have some numbers for this and duplicating that effort makes little sense. Moreover, this kind of data is typically the responsibility of the HR and/or finance department and it might not be wise politically to come up with alternative calculations.

Figure 9: Application portfolio dashboard
When you have an insight in these IT costs, the next step can be distributing these across the various business processes and business units of your enterprise based on the use they make of that IT, again using the relationships in your architecture model. This may land you in even more politically charged territory, however, since this will rapidly become a discussion about who should pay the bills. Nonetheless, in our experience creating these kinds of insights is very valuable. If you show what could be done to responsible management, they might rapidly ask for more. So, if you struggle to get heard by your executives, this may be one way to get their ear.
Risk, Security & Compliance Analyses
Finally, I want to address the domain of risk, security and compliance, an area of increasing importance for architects, process designers and others. You probably already know what the EU General Data Protection Regulation is. Elsewhere I’ve already written about it and its impact, and I used a simple example of data classification to illustrate how you can assess your application landscape.
But I have yet to demonstrate the full power of model-driven analysis techniques in relation to the GDPR – until now, that is. Starting with a classification of your data like in Figure 10, this classification can be propagated across your entire architecture model, where the meaning of the various elements and relationships is considered to provide a sensible and useful outcome.

Figure 10: Personal data classification
Assessing the impact of privacy and security
If an application has access to multiple data objects, the underlying analysis algorithm takes the highest level of classification from these objects as the norm for that application. So, if it uses both high- and medium-confidentiality data, it receives the highest classification. If this and other applications are used in a business process, that process receives the highest classification again. If some business role performs this and other processes, and if an actor perform several roles, the highest level again counts.
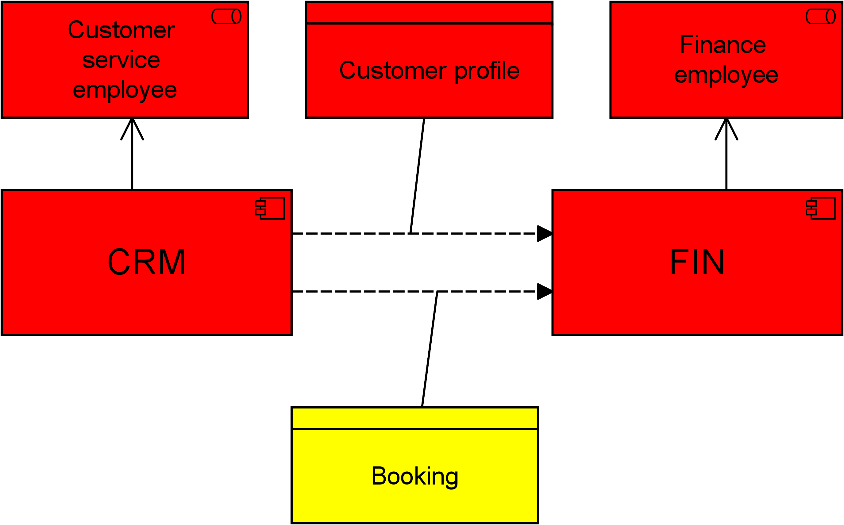
Figure 11: Coherent security classification
This even works for the relationship-to-relationship feature in ArchiMate 3.0, where you can, for instance, model what data is associated with a flow between two applications. If these two exchange highly sensitive data, they need to have at least that same security classification. Using this analysis provides you with a fast way to make an initial assessment of the impact of privacy, security and similar issues.
It helps CISOs, CROs, Data Protection Officers and others zoom in on high-risk areas this enables them to prioritize investments in order to beef up security where it is most needed and address security-by-design, data privacy impact assessments and other demands from regulations like the GDPR.
Try different scenarios to analyze vulnerabilities
Another even more advanced example is the risk assessment method we have implemented as part of our enterprise risk and security management functionality. This is based on a combination of standards such as ArchiMate, Open FAIR and SABSA, and is described in a whitepaper by The Open Group.
Using this method, you can use your architecture models to analyze what your vulnerabilities are, what the potential impact of internal and external threats could be, and thus identify ways to mitigate against these. Figure 12 shows an example of such an analysis.

Figure 12: Advanced risk assessment
All the ‘traffic lights’ in this figure are interconnected. For example, if you increase the control strength (CS) of the measures that mitigate against your vulnerabilities, your vulnerability level (Vuln) goes down, the loss event frequency (LEF) also decreases, and consequently your risk goes down. These results can also be presented in a more management-friendly way with heatmaps, such as in Figure 13.

Figure 13: Heat maps view of security assessment
Conclusion
Architectural models provide a fantastic opportunity for identifying key insights about your organization and the way it runs. Using the analyses I presented you should be able to create a lot of value moving forward. Even if you start slow, employing one or two types of analysis and then expanding gradually, you should start seeing real benefits as you slowly unlock the business value found in your architectural models.
Note: All examples were realized in the BiZZdesign Enterprise Studio & HoriZZon suite.
Author: Marc Lankhorst
Marc Lankhorst, Chief Technology Evangelist & Managing Consultant at BiZZdesign, is widely acknowledged as the “father of ArchiMate”, the de facto standard for modeling enterprise architecture. Marc has more than 20 years of experience as an enterprise architect, trainer, coach, and project manager. He has published extensively in the field of EA and is a regular speaker at conferences and seminars around the world.
BiZZdesign is a leading enterprise transformation software vendor based in the Netherlands. Founded in 2000 as the commercial spin-off of an R&D institute, today the company enjoys a global presence and is recognized by industry analysts as a market leader. BiZZdesign’s flagship product, Enterprise Studio, is deployed in blue chip companies and government organizations across all continents, where it plays a key role in enabling meaningful business change.