BRYCE ON SYSTEMS
– Five business process templates which accommodate most business processes.
 When we developed our Automated Systems Engineering (ASE) tool (originally called ADF – Automated Design Facility), it forced us to fine tune our concepts for system design. It was based on our concept of “Information Driven Design,” meaning it could deduce a complete system design based on the Information Requirements of the user. If the requirements were incorrect, the design was incorrect. However, in the hands of someone who understood requirements definition, it could save them considerable time in either designing a new system, or documenting an existing one.
When we developed our Automated Systems Engineering (ASE) tool (originally called ADF – Automated Design Facility), it forced us to fine tune our concepts for system design. It was based on our concept of “Information Driven Design,” meaning it could deduce a complete system design based on the Information Requirements of the user. If the requirements were incorrect, the design was incorrect. However, in the hands of someone who understood requirements definition, it could save them considerable time in either designing a new system, or documenting an existing one.
Based on requirements, ASE decomposes a system into its sub-systems (business processes), the procedural work flow for each, and determine what programs are necessary to implement the computer procedures (software specs). To do this, we determined there were three basic types of sub-systems:
* File Maintenance (aka Data Collection).
* Information Retrieval (queries in the form of reports and screens).
* A combination of both Maintenance and Retrieval.
This implies there are primarily two functions we can apply to files: Read (query) or Write (update).
One of the key design parameters was the timing of the Information Requirements. For example, the need for specific information on a daily basis, weekly, monthly, quarterly, etc., or Upon Request (aka “On Demand”).
To decompose sub-systems into procedural work flows, it is necessary to understand other properties, for example:
* All processing involves the use of transactions, either one at a time (such as to make a query), or volumes of transactions (such as “batch” processing).
* The workflow of a system involves the use of the processing constructs of sequence, iteration (repetition), and choice (branching). Further, the workflow has one or more “Starts” and continues uninterrupted until it reaches “End.”
Between the timing of the sub-system and transaction volume, we can make some assumptions in terms of procedural flow. For example, a sub-system needed “Upon Request” with a short response time (such as seconds) would inevitably result in an “interactive” sub-system; conversely, a daily or weekly process involving several transactions implies a “batch” process.
From these specifications, we can deduce standard business processes using templates. For example (Note: PROC = procedure):
TEMPLATE-1 – BATCH FILE MAINTENANCE
“Start”
PROC-1 – INPUT PREPARATION
PROC-2 – DATA CONVERSION – be it data entry, optical recognition, or some other form.
PROC-3 – UPDATE FILES – computer processing.
PROC-4 – REVIEW – to verify transactions were entered correctly (using a log) and implement necessary corrections.
“End”
Note: This is typically a sequential process.
TEMPLATE-2 – INTERACTIVE FILE MAINTENANCE
“Start”
PROC-1 – INPUT TRANSACTIONS, one at a time, through a screen. After reviewing data validation, either print, correct transaction, enter another transaction, or end.
PROC-2 – UPDATE FILES – computer processing producing data validation screen.
“End”
Note: This is typically an iterative process.
TEMPLATE-3 – INTERACTIVE QUERY
“Start”
PROC-1 – INPUT TRANSACTION representing a request, one at a time, through screen. After receiving information, either print, make another request, or end.
PROC-2 – READ FILES – computer processing to produce information on screen.
“End”
Note: This is typically an iterative process.
TEMPLATE 4 – BATCH REQUEST
“Start”
PROC-1 – INPUT TRANSACTION representing a request, either manually or scheduled.
PROC-2 – READ FILES – computer processing to produce reports.
PROC-3 – REVIEW AND DISTRIBUTE REPORTS
“End”
Note: This is typically used for such things as weekly/monthly payroll, weekly/monthly/quarterly/annual reports.
TEMPLATE-5 – INTERACTIVE READ/WRITE SELECTION
“Start”
PROC-1 – SELECT ACTION AND INPUT TRANSACTION through screen. If updating files, review data validation, either print, correct transaction, enter another transaction, return to menu to select another action, or end. If querying information, either print, make another request, return to menu to select another action, or end.
PROC-2 – READ/WRITE FILES – computer processing to either update files or produce information on screen.
“End”
Note: This is typically an iterative process.
When designing sub-systems, an application logical data base is created to service the data needs for all sub-systems, not just one. Then, as the sub-systems are designed into procedural flows, the application physical files can also be deduced, including working and primary files. Also, inputs and outputs are deduced and attached to the various processes.
These five templates represent the bulk of processing in companies. There may be other types of sub-systems to manage the overall system or to handle files, such as file initialization, backup, security, migration (import/export), but these five templates can be used by any business. Of course, such templates are modifiable to suit the nuances of a business, simply by adding or removing procedures.
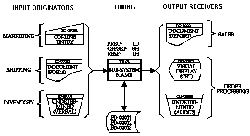
Pictorially, we flowchart the sub-systems and procedures using standard ASCII flowcharting symbols which depict both the processing flow and data flow.
Information Driven Design
This is all made possible by defining our terminology and concepts. Information Driven Design concentrates on the proper definition of information requirements. Timing will ultimately dictate how data will be collected and stored (availability requirements) and how data will be accessed to produce information. From this, we can deduce both processing and data requirements, thereby providing for design correctness.
When decomposing the system into sub-systems, the emphasis is to design backwards:
Information Requirements >>> Data Requirements
Receiver of Information >>> Originator of Data
Outputs >>> Inputs
Later, as the sub-systems are decomposed into procedures, the process is reversed. Here, the design expresses how data will physically be processed in order to produce information.
Source of Data >>> Destination of Info
Inputs >>> Outputs
Start >>> End
This is also true in determining the programming of computer procedures, from “Start” to “End.”
The required data must be defined in such a way that we can easily understand what primary data must be supplied by a User and what generated data must be calculated internal to the system. Data relationships can be extensive. For example, take NET-PAY which may be based on a complicated computation:
NET-PAY = GROSS-PAY – FICA – CITY-TAX – UNION-DUES – (etc.)
The data elements used in the formula may also be calculated, such as:
GROSS-PAY = HOURS-WORKED X PAY-RATE
This means in order to arrive at the correct value for NET-PAY, we must be able to reach all of the primary values, such as HOURS-WORKED and PAY-RATE, in a TIMELY manner. If we cannot do this, NET-PAY will be incorrect.
Information Driven Design and the use of standard processing templates greatly simplifies the design of systems, thereby saving time on the critical up-front work that is normally overlooked. The result is a viable design of both the processes and the data. This approach is universally applicable and based on tried and proven approaches fundamental to sound system design.
The hitch though remains defining the information requirements properly. If they are correct, the design will be correct. However, if they are incorrect, no amount of elegant programming will correct a flawed design.
Keep the Faith!
Note: All trademarks both marked and unmarked belong to their respective companies.
Author: Tim Bryce
 Tim Bryce is a writer and the Managing Director of M&JB Investment Company (M&JB) of Palm Harbor, Florida and has over 30 years of experience in the management consulting field. He can be reached at[email protected]
Tim Bryce is a writer and the Managing Director of M&JB Investment Company (M&JB) of Palm Harbor, Florida and has over 30 years of experience in the management consulting field. He can be reached at[email protected]
For Tim’s columns, see: timbryce.com
Copyright © 2015 by Tim Bryce. All rights reserved.