 When we first look at data fields on a business document, they appear complex. However once we analyze and understand them, they become simple. This is one of the purposes for a technique called normalization – to understand data fields and their relationships.
When we first look at data fields on a business document, they appear complex. However once we analyze and understand them, they become simple. This is one of the purposes for a technique called normalization – to understand data fields and their relationships.
This article starts with a challenge of understanding the data fields on a business document. It then proceeds with six brief lessons in analyzing the document by analyzing the data fields through six “normal forms.” We call this analysis “data normalization.” Note that typically data analysis covers only the first three normal forms. For completeness, this article includes all six normal forms, plus a glossary of some normalization terms.
Data Fields at First Look – Employee Record
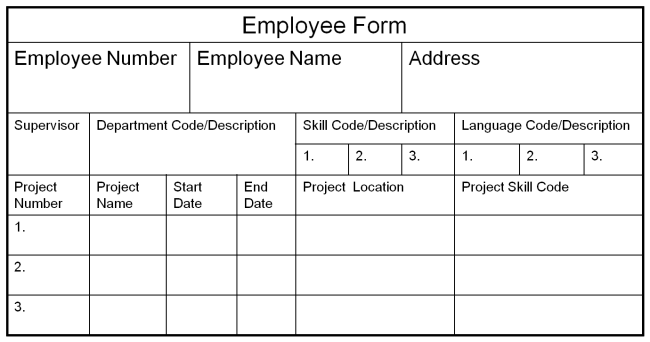
Figure 1. Document for Analysis – Employee Record
Figure 1 depicts a business document, “Employee Record.” It contains various data fields concerning employee information. Let’s place all the data fields in a group and name it EMPLOYEE. In documenting the group, we enclose the data fields in parenthesis, separate each data field by a comma, and underline a data field(s) that uniquely identifies the group. In this case, the data field, employee number, uniquely identifies the group. Note we document data fields that occur multiple times as plural - e.g., skill(s). In addition, we can interject some jargon by calling the group an entity, the data items of the entity, attributes, and the unique identifier, the key; see glossary for all terms in italics.
| EMPLOYEE |
( employee number, employee name, address, supervisor, department code, department description, skill code(s), skill description(s), language code(s), language description(s), project number(s), project name(s), start date(s), end date(s), project location(s), project skill(s) ) |
Figure 2. EMPLOYEE Entity
First Normal Form – 1NF
 Our goal is to simplify the EMPLOYEE entity so that we can better understand it. To accomplish this, we use a process called normalization. The first step is to remove the data items that occur multiple times within the entity (i.e., attributes non-repeating). We remove the repeating data items by creating associative entities.
Our goal is to simplify the EMPLOYEE entity so that we can better understand it. To accomplish this, we use a process called normalization. The first step is to remove the data items that occur multiple times within the entity (i.e., attributes non-repeating). We remove the repeating data items by creating associative entities.
| EMPLOYEE |
( employee number, name, address, supervisor, department code, department description ) |
| EMPLOYEE-LANGUAGE |
( employee number, skill code, language code, skill description, language description ) |
| EMPLOYEE-PROJECT |
( employee number, project number, project location, start date, end date, project name, project skill ) |
Figure 3. First Normal Form Entities - Attributes Non-Repeating
We create an associate entity by moving the repeating data field to a new entity and duplicating the key of the original entity – employee number. In order to preserve the repeating nature of the attribute, we create a concatenate key consisting of employee number and the unique identifier of the repeating attributes. The results are three entities each containing non-repeating attributes (i.e., first normal form).
Special Notes:
-
In the case of the EMPLOYEE-PROJECT entity, there are three components to the concatenate key since an employee can work for different projects at different locations. There is an implied business rule that we will discuss fourth normal form.
-
In the case of the EMPLOYEE-SKILL-LANGUAGE entity, there are three components to the concatenate key since an employee can have multiple skills and know multiple languages. However, not all the key components have dependency with each other; more on this when we discuss fifth normal form.
Second Normal Form – 2NF
 Our second step to simplicity is to ensure that the first normal form entity attributes are dependent on the key of the entity (i.e., attribute key dependency); in cases of concatenated key attributes, the dependency must be with the entire key. In entities, EMPLOYEE-SKILL-LANGUAGE, and EMPLOYEE-PROJECT, we find attributes, skill description, language description, and project name, dependent only on part of the key of the entities. As before, we create an associate entity by removing the partially dependent key attribute and duplicating the partial key of the original entity. Note that by duplicating the partial key we maintain a relationship with the original entity. The results are six entities each containing key dependent attributes (i.e., second normal form).
Our second step to simplicity is to ensure that the first normal form entity attributes are dependent on the key of the entity (i.e., attribute key dependency); in cases of concatenated key attributes, the dependency must be with the entire key. In entities, EMPLOYEE-SKILL-LANGUAGE, and EMPLOYEE-PROJECT, we find attributes, skill description, language description, and project name, dependent only on part of the key of the entities. As before, we create an associate entity by removing the partially dependent key attribute and duplicating the partial key of the original entity. Note that by duplicating the partial key we maintain a relationship with the original entity. The results are six entities each containing key dependent attributes (i.e., second normal form).
| EMPLOYEE |
( employee number, name, address, supervisor, department code, department description ) |
| SKILL |
( skill code, skill description ) |
| EMPLOYEE-SKILL-LANGUAGE |
( employee number, skill code, language code ) |
| LANGUAGE |
( language code, language description ) |
| EMPLOYEE-PROJECT |
( employee number, project number, start date, end date, project location, project skill ) |
| PROJECT |
( project number, project name ) |
Figure 4. Second Normal Form Entities - Attribute Key Dependency
Special Note: We need to ensure that all data field values have a place in the entities. For example, suppose that department, skill, language descriptions were not in the “Employee Record” document (Figure 1). As a result, we would not have created the entities of SKILL and LANGUAGE during the second normal form step. However, the resulting entities would only capture the data field values for department, skill, language codes that existed for an employee in the EMPLOYEE and EMPLOYEE-LANGUAGE entities in Figure 4.
Third Normal Form – 3NF
 Our third step to simplicity is to ensure the second normal form entity attributes are independent of each other (i.e., attribute non-key independency). In entity, EMPLOYEE, we find a dependency between attributes, department code and department description. As before, we create an associate entity by removing the dependent non-key attribute, department description, and duplicating the attribute that it is dependent on, department code, as the key of the new entity. Note once again by duplicating the attribute that it is dependent on, department code, we maintain a relationship with the original entity; department code in the original entity is referred to as a foreign key. The results are eight entities each containing independent non-key attributes (i.e., third normal form).
Our third step to simplicity is to ensure the second normal form entity attributes are independent of each other (i.e., attribute non-key independency). In entity, EMPLOYEE, we find a dependency between attributes, department code and department description. As before, we create an associate entity by removing the dependent non-key attribute, department description, and duplicating the attribute that it is dependent on, department code, as the key of the new entity. Note once again by duplicating the attribute that it is dependent on, department code, we maintain a relationship with the original entity; department code in the original entity is referred to as a foreign key. The results are eight entities each containing independent non-key attributes (i.e., third normal form).
| EMPLOYEE |
( employee number, name, address, supervisor, department code ) |
| DEPARTMENT |
( department code, department description ) |
| SKILL |
( skill code, skill description ) |
| EMPLOYEE-SKILL-LANGUAGE |
( employee number, skill code, language code ) |
| LANGUAGE |
( language code, language description) |
| EMPLOYEE-PROJECT |
( employee number, project number, project location, start date, end date, project skill ) |
| PROJECT |
( project number, project name ) |
Figure 5. Third Normal Form Entities - Attribute Non-Key Independency
Sync-Point at Third Normal Form
At this point, we have simplified the document, “Employee Record.” Through the normalization process so far, we have gained a better understanding of the data fields by creating entities, their keys, attributes and relationships; note that normalization is a cumulative process (i.e., third normal form entities are inherently in second normal form, which are also in first normal form).
So what have we learned so far about employees through normalizing the data fields in this business document (i.e., data business rules)?
-
All employees have an employee number that uniquely identifies them.
-
Each employee has one address, one supervisor and works in one department.
-
An employee may have multiple skills and know multiple languages.
-
An employee may work on multiple projects for a finite period at different locations using different skills.
Many data analysis are complete upon accomplishing third normal form. However, in some data analysis we need to go further. Remember we noted in the case of the EMPLOYEE-SKILL-LANGUAGE and EMPLOYEE-PROJECT entities, there remains some complexity.
Beyond Third Normal Form – 4NF and 5NF
The purpose of fourth and fifth normal form is to understand the composite keys of the entities. Let’s first look at the EMPLOYEE-SKILL-LANGUAGE entity.
| EMPLOYEE-SKILL-LANGUAGE |
( employee number, skill code, language code ) |
Figure 6. EMPLOYEE-SKILL-LANGUAGE Entity
 In examining the composition of the key, we find that there are only two dependent relationships: an employee can have many skills and an employee can know many languages. However, there is no relationship between an employee with a skill and the same employee knowing a language (i.e., they are independent). We need to simplify the concatenate key by separating the dependent relationships, remove the original entity and create two new entities.
In examining the composition of the key, we find that there are only two dependent relationships: an employee can have many skills and an employee can know many languages. However, there is no relationship between an employee with a skill and the same employee knowing a language (i.e., they are independent). We need to simplify the concatenate key by separating the dependent relationships, remove the original entity and create two new entities.
This is fourth normal form – ensuring the key components of a third normal form entity are dependent as done in Figure 7 (i.e., key components dependency).
| EMPLOYEE-SKILL |
( employee number, skill code ) |
| EMPLOYEE-LANGUAGE |
( employee number, language code ) |
Figure 7. Fourth Normal Form Entities - Key Components Dependency
Special Note: If the implied business rule is an employee with a skill is limited to only certain languages, then there is a dependency between an employee with a certain skill and language (e.g., can only type in English and Spanish). With this rule, the entity EMPLOYEE-SKILL-LANGUAGE in Figure 6 is in fourth normal form.
 An entity is in fifth normal form when it is in fourth normal form and you cannot construct the entity by joining other entities (i.e., key relationship decomposed). For example, consider our entity EMPLOYEE-PROJECT with a concatenated key of employee number, project name, project location.
An entity is in fifth normal form when it is in fourth normal form and you cannot construct the entity by joining other entities (i.e., key relationship decomposed). For example, consider our entity EMPLOYEE-PROJECT with a concatenated key of employee number, project name, project location.
| EMPLOYEE-PROJECT |
( employee number, project number, project location, start date, end date, project skill ) |
Figure 8. EMPLOYEE-PROJECT Entity
Suppose there is an implied business rule that when (start date to end date) an employee works on a project, the employee uses the same skill at all project locations associated with the project. Given this rule, we can construct EMPLOYEE-PROJECT-LOCATION by joining other entities such EMPLOYEE-PROJECT, PROJECT-LOCATION across the keys: employee number, project number, and project location in Figure 9.
| EMPLOYEE-PROJECT |
( employee number, project number, start date, end date, project skill ) |
| PROJECT-LOCATION |
( project number, project location ) |
Figure 9. Fifth Normal Form Entities - Key Relationship Decomposed
Special Note: If the implied business rule is when an employee works on a project, the employee works at only certain locations (not all), then we cannot construct EMPLOYEE-PROJECT from other entities. With this rule, the entity EMPLOYEE-PROJECT in Figure 8 is in fifth normal form.
But Wait, There’s More – 6NF
 Sixth normal form entities are in fifth normal form and handle the concept of time (i.e., key temporal aspects). Does the entity represent the current situation or history? For example, consider the entity EMPLOYEE-PROJECT in Figure 9. Suppose there is an implied business rule that when an employee works for a project, the employee is allowed to use one and only one skill per project location per stated time period. By using time data fields, start date and end date, as key components, we can create historical and current oriented entities; see Figure 10.
Sixth normal form entities are in fifth normal form and handle the concept of time (i.e., key temporal aspects). Does the entity represent the current situation or history? For example, consider the entity EMPLOYEE-PROJECT in Figure 9. Suppose there is an implied business rule that when an employee works for a project, the employee is allowed to use one and only one skill per project location per stated time period. By using time data fields, start date and end date, as key components, we can create historical and current oriented entities; see Figure 10.
| EMPLOYEE-PROJECT-CURRENT |
( employee number, project number, start date, end date, project skill ) |
| EMPLOYEE-PROJECT- HISTORY |
( employee number, project number, start date, end date, project skill ) |
Figure 10. Sixth Normal Form Entities - Key Temporal Aspects
The final product (Figure 11) of normalization is a logical data map that a data architect uses as a structural basis for physical implementation.
EMPLOYEE
|
( employee number, name, address, supervisor, department code ) |
| DEPARTMENT |
( department code, department description ) |
| SKILL |
( skill code, skill description ) |
| LANGUAGE |
( language code, language description ) |
| PROJECT |
( project number, project name ) |
| EMPLOYEE-SKILL |
( employee number, skill code ) |
| EMPLOYEE-LANGUAGE |
( employee number, language code ) |
| PROJECT-LOCATION |
( project number, project location ) |
| EMPLOYEE-PROJECT-CURRENT |
( employee number, project number, start date, end date, project skill ) |
| EMPLOYEE-PROJECT- HISTORY |
( employee number, project number, start date, end date, project skill ) |
Figure 11. Final Entities in Sixth Normal Form
Summary
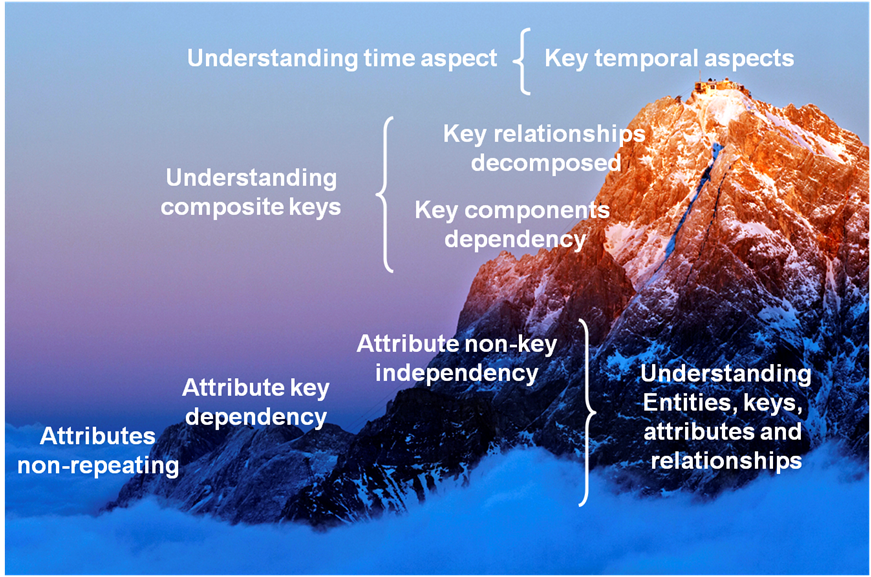
Figure 11. Cumulative Forms of Normalization
As stated at the beginning of this article, data analysis typically focuses on understanding keys and attributes. They cover only the first three normal forms of entities: (1NF) attributes non-repeating, (2NF) attributes key dependency, and (3NF) attribute non-key independency. However, you may need to include (4NF) dependency, (5NF) decomposition, and (6NF) temporal aspects of concatenated key components of entities.
Post Script
This article focuses on understanding data fields via normalization. Another purpose of normalization is to eliminate data anomalies associated with maintaining data such as data redundancy and integrity. This article does not directly address those benefits nor does it discuss the data architect consciously de-normalizing the data for physical database performance reasons.
Glossary of Some Normalization Terms
-
Attribute – a characteristic of an entity Concatenated Key – an entity key that consist of multiple attributes
-
Business Rule – a statement that defines or constrains business behavior
-
Normalization – a process that simplifies data for the purpose of understanding the data and eliminating update anomalies; process consists of steps called normal forms
-
First Normal Form (1NF) – state of an entity having have no repeating attributes
-
Second Normal Form (2NF) – state of an entity which is in 1NF and all attributes are dependent on the entity key (entire concatenated key)
-
Third Normal Form (3NF) – state of an entity which is in 2NF and all attributes are independent of each other
-
Fourth Normal Form (4NF) – state of an entity which is in 3NF and components of the concatenated key are dependent on each other
-
Fifth Normal Form (5NF) – state of an entity which is in 4NF and cannot be constructed by joining other entities
-
Sixth Normal Form (6NF) – state of an entity which in 5NF and addresses current or historical views of time
-
Entity – any object (real or abstract) that is of concern to the business
-
Foreign Key – a key of an entity that is a non-key attribute in another entity
-
Key – attribute(s) that uniquely identify an entity
-
Join – the result of combining two or more entities across common attributes
Further Reading
-
Codd, E. F., A Relational Model of Data for Large Shared Data Banks, Communications of the ACM, (June 1970)
-
Date, C. J., An Introduction to Database Systems, Addison-Wesley, (1999)
-
Date, C.J., Darwen, Hugh, Lorentzos, Nikos, Temporal Data & the Relational Model, First Edition (The Morgan Kaufmann Series in Data Management Systems); Morgan Kaufmann; 1st edition (2002)
-
Fagin, Ronald, Multivalued Dependencies and a New Normal Form for Relational Databases, ACM Transactions on Database Systems (September 1977)
-
Heath, I., Unacceptable File Operations in a Relational Database, Proc. 1971 ACM SIGFIDET Workshop on Data Description, Access, and Control, San Diego, Calif. (November 11th–12th, 1971)
Related Data Webinar: Webinar: Got Big Data? How can you combine the Big Data with traditional enterprise data?
 Author: Mr. Monteleone holds a B.S. in physics and an M.S. in computing science from Texas A&M University. He is certified as a Project Management Professional (PMP®) by the Project Management Institute (PMI®), a Certified Business Analysis Professional (CBAP®) by the International Institute of Business Analysis (IIBA®), a Certified ScrumMaster (CSM) and Certified Scrum Product Owner (CSPO) by the Scrum Alliance, and certified in BPMN by BPMessentials. He holds an Advanced Master’s Certificate in Project Management (GWCPM®) and a Business Analyst Certification (GWCBA®) from George Washington University School of Business. Mark is the President of Monteleone Consulting, LLC and can be contacted via – www.baquickref.com.
Author: Mr. Monteleone holds a B.S. in physics and an M.S. in computing science from Texas A&M University. He is certified as a Project Management Professional (PMP®) by the Project Management Institute (PMI®), a Certified Business Analysis Professional (CBAP®) by the International Institute of Business Analysis (IIBA®), a Certified ScrumMaster (CSM) and Certified Scrum Product Owner (CSPO) by the Scrum Alliance, and certified in BPMN by BPMessentials. He holds an Advanced Master’s Certificate in Project Management (GWCPM®) and a Business Analyst Certification (GWCBA®) from George Washington University School of Business. Mark is the President of Monteleone Consulting, LLC and can be contacted via – www.baquickref.com.